
공식문서
https://milvus.io/docs/ko/overview.md
Milvus
강력한 데이터 모델링 기능을 제공하여 ‘비정형 데이터’ 또는 ‘멀티모달 데이터’를 정형화된 컬렉션으로 구성
벡터(Vector) 데이터를 위한 고성능 오픈소스 벡터 데이터베이스
비정형 데이터를 임베딩(숫자 벡터)한 후, 유사도 기반 검색을 빠르게 처리할 수 있게 도와줌
비정형 데이터
형태나 구조가 일정하지 않아 정형화된 데이터베이스에 바로 넣기 어려운 데이터
벡터 DB 사용
문장, 이미지, 오디오 등 ‘비정형 데이터’를 효율적으로 검색하고 유사도를 기반으로 빠르게 찾아내기 위함입
멀티모달 데이터
두 개 이상의 서로 다른 형태(모달리티)의 데이터를 결합
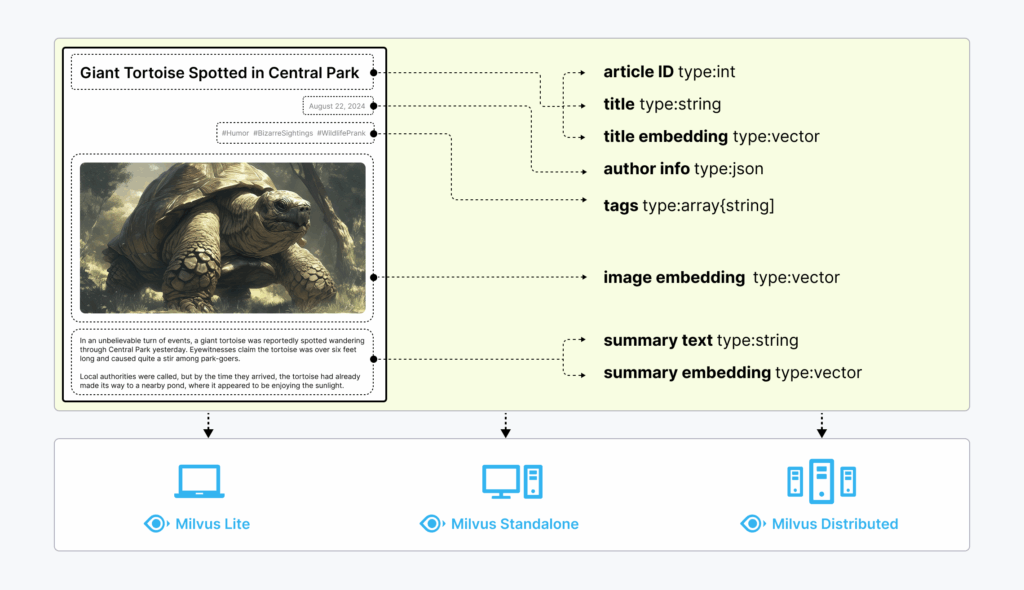
Milvus 배포 모드
Milvus Lite
Milvus의 경량 버전으로, Jupyter Notebook에서 빠르게 프로토타이핑하거나 리소스가 제한된 엣지 기기에서 실행
Milvus Standalone
단일 머신 서버 배포로, 모든 구성 요소가 단일 Docker 이미지에 번들로 제공되어 편리하게 배포할
Milvus Distributed
수십억 규모 또는 그 이상의 시나리오를 위해 설계된 클라우드 네이티브 아키텍처를 특징으로 하는 Kubernetes 클러스터에 배포
Milvus가 지원하는 검색 유형
Milvus는 다양한 사용 사례의 요구 사항을 충족하기 위해 다양한 유형의 검색 기능을 지원합니다:
- ANN 검색: 쿼리 벡터와 가장 가까운 상위 K 벡터를 찾습니다.
- 필터링 검색: 지정된 필터링 조건에 따라 ANN 검색을 수행합니다.
- 범위 검색: 쿼리 벡터에서 지정된 반경 내의 벡터를 찾습니다.
- 하이브리드 검색: 여러 벡터 필드를 기반으로 ANN 검색을 수행합니다.
- 전체 텍스트 검색: BM25에 기반한 전체 텍스트 검색.
- 순위 재조정: 추가 기준 또는 보조 알고리즘을 기반으로 검색 결과의 순서를 조정하여 초기 ANN 검색 결과를 개선합니다.
- 가져오기: 기본 키로 데이터를 검색합니다.
- 쿼리: 특정 표현식을 사용해 데이터를 검색합니다.

